When working with Java, two commonly used data structures are HashMap and HashSet. These collections are highly efficient, but their efficiency relies on how they handle internal operations, especially when it comes to collisions. This blog will explain the internal workings of HashMap and HashSet in simple terms and provide examples to help you understand how they manage collisions.
What is a HashMap?
A HashMap is a data structure that stores key-value pairs. It allows you to store data in a way that lets you quickly retrieve the value associated with a specific key. The keys in a HashMap must be unique.
Internal Working of HashMap
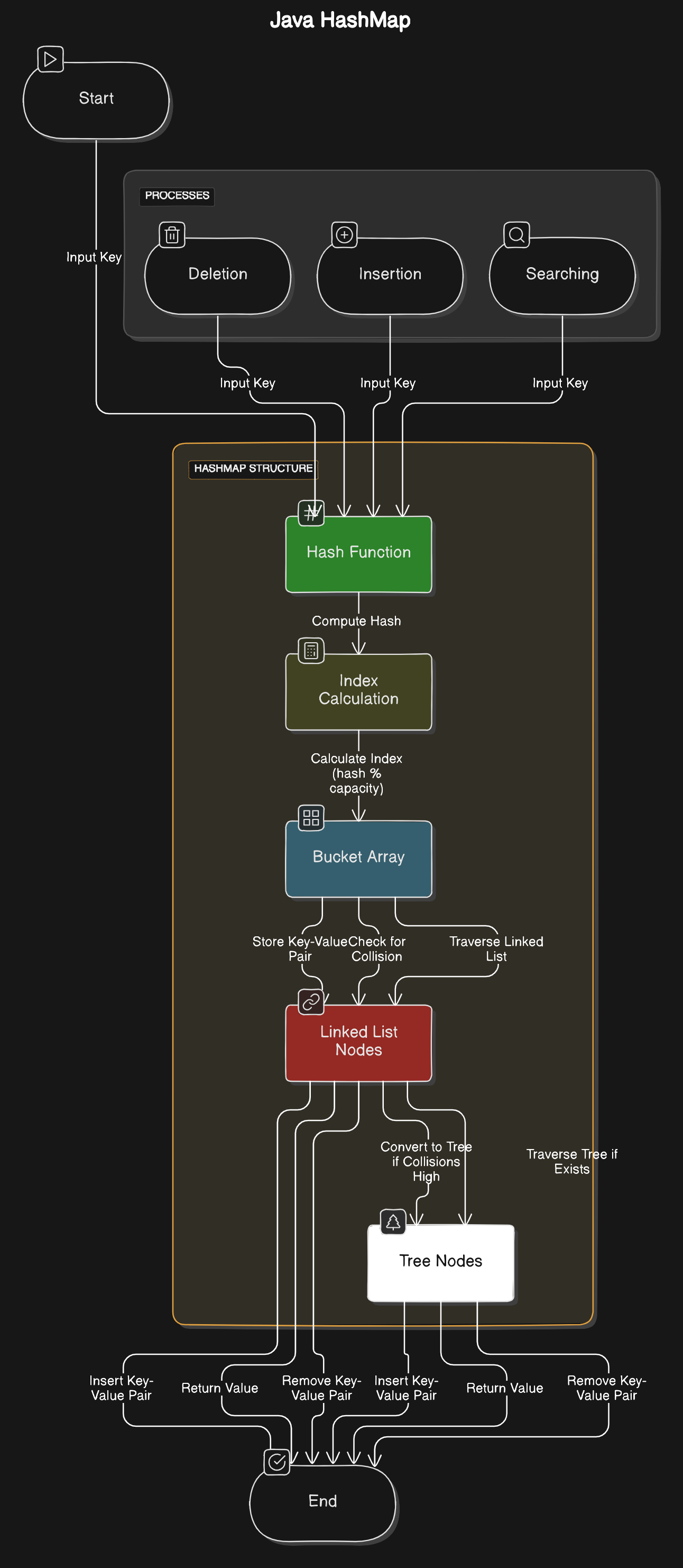
Buckets and Hash Codes
- Buckets: Internally, a
HashMapuses an array of buckets to store entries (key-value pairs). The bucket where a key-value pair is stored is determined by the key’s hash code. - Hash Code: When you add a key-value pair to the
HashMap, Java calculates the hash code of the key. This hash code is then used to determine which bucket the entry should be placed in.
Handling Collisions
A collision occurs when two different keys produce the same hash code, resulting in them being assigned to the same bucket.
Linked List (Java 7 and Earlier):
- Before Java 8, if a collision occurred, the
HashMapwould store the collided entries in a linked list within that bucket. - To retrieve a value, Java would traverse the linked list in the bucket and compare each key using the
equals()method until it found the correct one.
- Before Java 8, if a collision occurred, the
Tree-based Structure (Java 8 and Later):
- Starting with Java 8, if a bucket contains a lot of entries (due to collisions), the
HashMapconverts the linked list into a balanced binary tree. - This change was made to improve performance, as searching in a tree is faster (O(log n)) compared to searching in a linked list (O(n)).
- Starting with Java 8, if a bucket contains a lot of entries (due to collisions), the
Rehashing:
- When the
HashMapbecomes too full (exceeding a load factor, usually 0.75), it increases the size of its bucket array and rehashes all entries to redistribute them more evenly across the new buckets. This reduces collisions and keeps theHashMapefficient.
- When the
HashMap Example
import java.util.HashMap;
import java.util.Objects;
public class Main {
public static void main(String[] args) {
HashMap<CustomKey, String> map = new HashMap<>();
CustomKey key1 = new CustomKey(1, "Key1");
CustomKey key2 = new CustomKey(1, "Key2"); // Same hash code as key1
System.out.println("Key1: " + key1.hashCode());
System.out.println("Key2: " + key2.hashCode());
map.put(key1, "Value1");
map.put(key2, "Value2");
System.out.println("Key1: " + map.get(key1));
System.out.println("Key2: " + map.get(key2));
}
}
class CustomKey {
private int id;
private String name;
public CustomKey(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public int hashCode() {
return Objects.hash(id); // Simplified hash code to force collision
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null || getClass() != obj.getClass())
return false;
CustomKey customKey = (CustomKey)obj;
return id == customKey.id && Objects.equals(name, customKey.name);
}
}
Key1: 32
Key2: 32
Key1: Value1
Key2: Value2
The code defines a CustomKey class with overridden hashCode and equals methods to demonstrate hash collisions in a HashMap. Two CustomKey objects with the same id but different name values are created, resulting in the same hash code but different equality checks. The HashMap stores and retrieves values using these keys, showing how collisions are handled.
What is a HashSet?
A HashSet is a collection that stores unique elements. It does not allow duplicate entries, and it is implemented using a HashMap internally.
Internal Working of HashSet
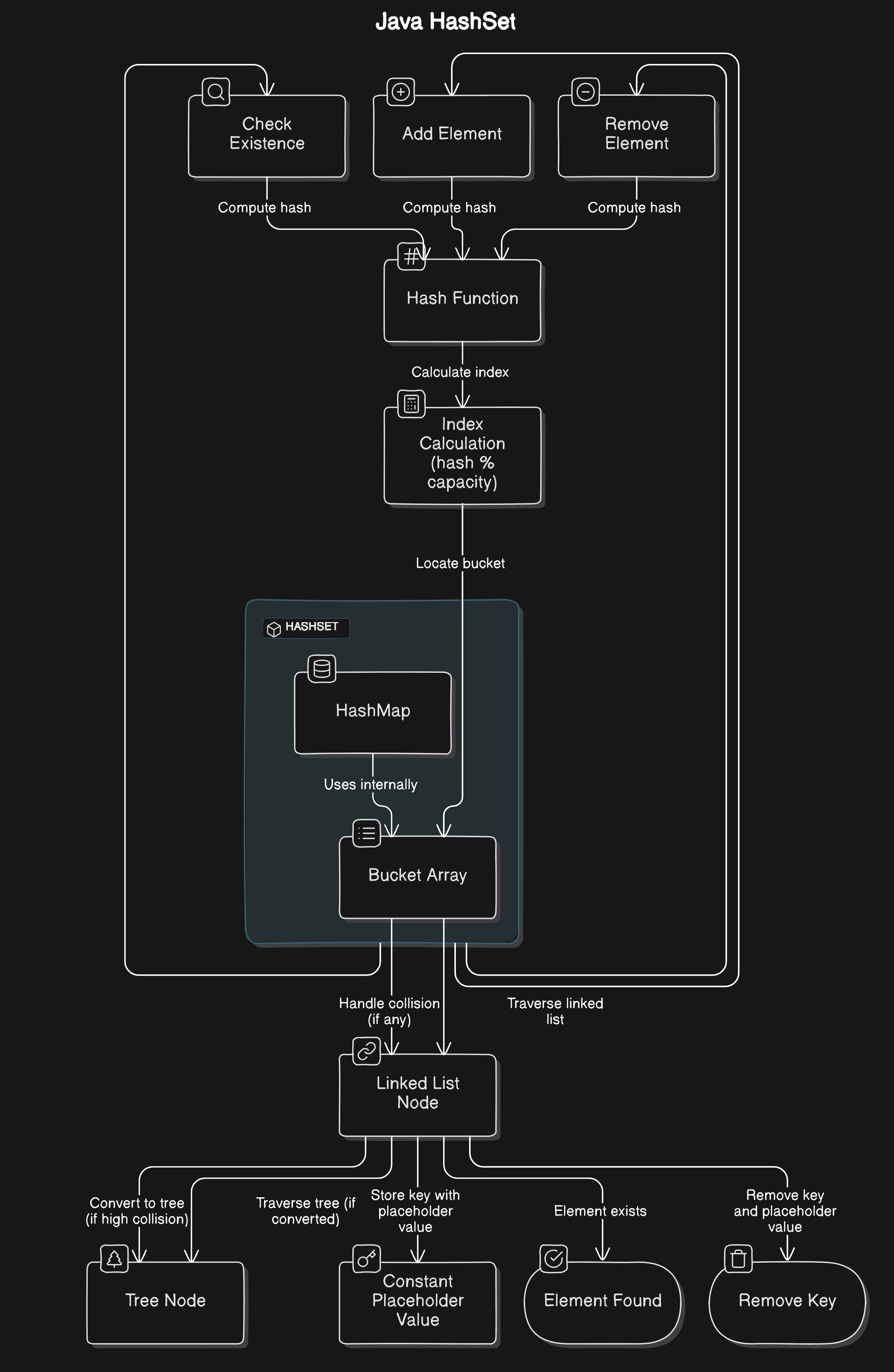
- Underlying HashMap: When you add an element to a
HashSet, it is stored as a key in aHashMapwith a dummy value (usuallyBoolean.TRUE). This is becauseHashMapkeys must be unique, which ensures that theHashSetonly stores unique elements.
Handling Collisions
Collisions in a HashSet are handled in the same way as in a HashMap, since HashSet is essentially a HashMap without values.
Linked List (Java 7 and Earlier):
- If two elements have the same hash code and are placed in the same bucket, they are stored in a linked list within that bucket.
Tree-based Structure (Java 8 and Later):
- In Java 8 and later, if a bucket’s linked list becomes too long due to collisions, it is converted into a balanced binary tree to improve search efficiency.
Rehashing:
- Similar to
HashMap, when theHashSetbecomes too full, it resizes its underlyingHashMap, rehashes all elements, and redistributes them across the new buckets.
- Similar to
HashSet Example
import java.util.HashSet;
import java.util.Objects;
public class Main {
public static void main(String[] args) {
HashSet<CustomKey> set = new HashSet<>();
CustomKey key1 = new CustomKey(1, "Key1");
CustomKey key2 = new CustomKey(1, "Key2"); // Same hash code as key1
System.out.println("Key1: " + key1.hashCode());
System.out.println("Key2: " + key2.hashCode());
System.out.println("equals: " + key1.equals(key2));
set.add(key1);
set.add(key2);
System.out.println("HashSet: " + set);
}
}
class CustomKey {
private int id;
private String name;
public CustomKey(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public int hashCode() {
return Objects.hash(id); // Simplified hash code to force collision
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null || getClass() != obj.getClass())
return false;
CustomKey customKey = (CustomKey)obj;
return id == customKey.id && Objects.equals(name, customKey.name);
}
@Override
public String toString() {
return "CustomKey{id=" + id + ", name='" + name + "'}";
}
}
Key1: 32
Key2: 32
HashSet: [CustomKey{id=1, name='Key1'}, CustomKey{id=1, name='Key2'}]
A HashSet in Java ensures uniqueness of its elements based on both the hashCode and equals methods. Here’s how it works:
Hashing: When an element is added to the
HashSet, itshashCodemethod is called to determine the hash code of the element. This hash code is used to find the appropriate bucket.Equality: If the hash code matches an existing element’s hash code in the same bucket, the
equalsmethod is then called to check if the two elements are actually equal. Ifequalsreturnstrue, the new element is considered a duplicate and is not added to the set.
In the provided code, the CustomKey class overrides both hashCode and equals methods. The hashCode method is simplified to force a collision by only using the id field, while the equals method checks both id and name fields for equality. This means that even if two CustomKey objects have the same id (and thus the same hash code), they will only be considered equal if both their id and name fields match.
Conclusion
Understanding how HashMap and HashSet handle collisions internally is crucial for optimizing their use in your applications. By knowing how buckets, linked lists, and trees work together to manage collisions, you can appreciate the efficiency and robustness of these data structures in Java.