Once upon a time, there was a baker who baked the perfect giant cake. It was huge, heavy, and costly to make. People loved it, but soon everyone started asking for different flavors:
- “Can I get chocolate?” 🍫
- “How about strawberry?” 🍓
- “What if you add coffee and almonds?” ☕🌰
The baker sighed. “I can’t bake a new giant cake every time… it’s too expensive!”
That’s when the idea struck: 👉 Don’t bake a new cake. Just add a topping.
And that, in the world of AI, is exactly what LoRA (Low-Rank Adaptation) does.
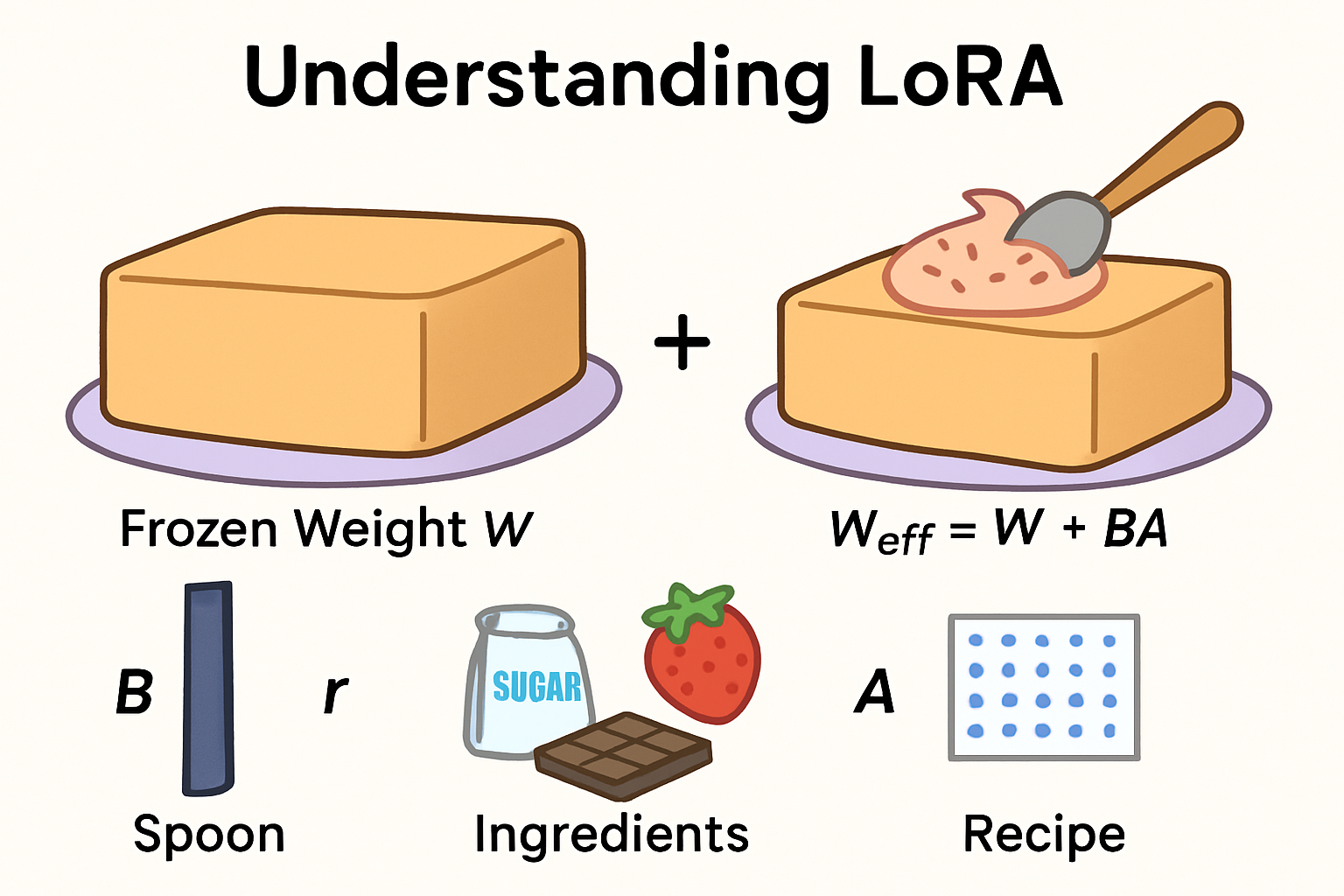
The Cake and the Topping
- W = the giant cake (frozen) → This is the pretrained model. Already baked. We don’t touch it.
- ΔW = the topping → A small patch we add on top of the cake to give it a new flavor.
Mathematically:
ΔW = B × A
- A = the recipe (what flavors to mix).
- B = the spoon (spreads the topping over the cake).
- r = the number of ingredients in the recipe.
Small r → simple topping (sugar + cream). Large r → fancy topping (nuts, fruits, chocolate swirls).
Why It Fits Perfectly
If the big cake (W) is a rectangle of size (k × d):
- B = (k × r) → tall and skinny
- A = (r × d) → short and wide
Multiply them:
(k × r) × (r × d) = (k × d)
That’s the exact shape of W. So we can safely add the topping:
W_eff = W + (B × A)
No mismatch, no mess. Just the perfect topping on the perfect cake.
Training Like a Baker
Each round of training is just like the baker testing toppings:
- Serve a slice → The model makes a prediction (forward pass).
- Listen to feedback → Compare prediction vs. truth (loss).
- Adjust the recipe → Update A and B (backpropagation).
- Try again → Small tweak, better flavor.
The base cake (W) never changes. Only the topping (A & B) gets updated — yet the taste (W_eff) keeps improving.
A Quick Example
Say W is a 4×4 cake. Instead of retraining all 16 numbers, LoRA creates two smaller matrices (A and B). Multiply them → you get ΔW, also 4×4.
Add it on top:
W_eff = W + ΔW
During training:
- W stays frozen.
- Only A and B move.
- Over many steps, small tweaks to A and B completely shift how the model behaves — just like how a little frosting can totally change the taste of a cake.
Why Everyone Loves LoRA
Just like the baker’s trick saved time and money, LoRA gives AI the same benefits:
- 🚀 Faster → No need to retrain billions of parameters.
- 💾 Lighter → Uses less memory.
- 💸 Cheaper → Huge savings on compute.
- 🔄 Flexible → You can swap toppings (fine-tunes) without touching the base cake.
💡 Final Thought: LoRA is like being a smart baker. Instead of wasting effort baking new cakes, you keep one perfect base cake and just swap the toppings to create endless flavors. Efficient, creative, and delicious.